虽然打星际输给了AI,但人类尚未一败涂地
《星际争霸2》的职业选手迎来了在人工智能面前的第一次惨败。
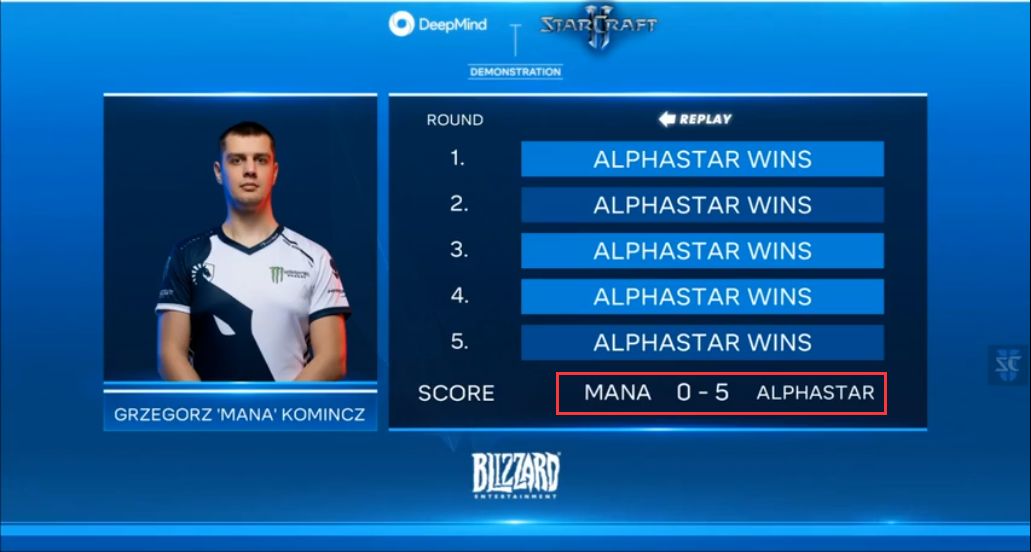
北京时间1月25日凌晨,谷歌旗下人工智能团队DeepMind公布了其开发的AI“AlphaStar”与《星际争霸2》职业选手TLO和MaNa的比赛录像。AlphaStar与两人的比赛相隔约半个月,以两场“5:0”取得完胜。
“不作弊”的AI
这是DeepMind为《星际争霸2》所开发AI的首次亮相。
AlphaStar和以往的《星际争霸2》游戏AI有着本质上的区别——而且,这个区别和实力强弱没关系。
和读取API接口、直接在程序层面操作的传统游戏AI不同,AlphaStar的操作由一个深度神经网络生成,获取信息和操作游戏的方式类似真人。它先从原生游戏界面上收集信息,在处理完信息后再把一连串指令输出在游戏画面上。
在DeepMind公布的AlphaStar的第一视角Replay里,我们能看到AI有逻辑非常接近人类 的“框选”“点击”“切屏”等操作,并不像传统AI那样让所有游戏行为在程序层面瞬间完成。

AlphaStar的行为逻辑也不来自人工编写。它在学习人类的对局录像掌握初步玩法后,就像它的兄弟AlphaGo一样,进入了“左右互搏”、自己和自己练习的过程。而且AlphaStar的对练对象不止一个人——DeepMind为它制造了数百个“分身”,直接模拟出了一个虚拟的天梯进行训练。

从今天发布的录像来看,不到一年时间过去,从“虚拟天梯”中爬出的AlphaStar在面对人类职业选手时已经具备了相当高的威胁性。
十比一的惨败
DeepMind今天公布的两场比赛,都发生在地图汇龙岛(Catalyst LE)上。
由于AlphaStar目前只学习了星灵VS星灵的打法,人类和AI都只能以星灵种族进行内战。并且,AlphaStar的视距被拉到最远,能够读取整张地图上的信息(不能穿透战争迷雾)。

首先上场的是Liquid战队的虫族选手TLO,目前在Aligulac的世界排名中位列72名。
第一局开始,TLO采用了非常传统的双兵营封路开局,侦查到AlphaStar并未封路后,TL0派出使徒骚扰取得了一定战果。但在进入到中局后,微操完全不敌AlphaStar的TLO被AI单矿一波直接莽穿。
第二局的情形就更一边倒,AlphaStar选择了出自爆球进攻,TLO显得完全没有应对经验,自己的部队被炸成了漫天烟花。

由于时间原因,现场只演示了这两场的录像,想看其他三场对局需要登陆DeepMind网站下载。
AS和TLO的对局算不上精彩,由于TLO的主族是虫族,使用星灵时完全没有人类顶级选手的实力,甚至还犯下了业余选手都不会犯的细节错误。
相比之下,AlphaStar和MaNa的对局更有象征意义。
这场比赛发生在两周以后(AlphaStar期间加练了相当于人类选手玩400年左右的局数),
MaNa的主族是星灵,其单族排名目前为世界第11,实力在二线职业选手中属于顶尖。

第一局中,AlphaStar选择了野兵营Rush,MaNa侦查到了AI的进攻意向,但是在AI极度精湛的小规模微操下并未防守住,打出GG。第二局双方都选择了爆凤凰,MaNa在小规模接战中被持续压制,最后被AlphaStar的兵力优势和无解操作打败。

之后对局的情形也类似,即在运营没有明显落后的情况下,MaNa被AlphaStar用高强度的操作硬吃了个5:0。
但在第六局,也是现场演示的唯一一局中,为了保护人类选手,DeepMind使用了AlphaStar的弱化版本,AI只能先切屏再操作,不能全屏操作。
在对抗这个弱化版的AI时,MaNa发现了AlphaStar似乎完全分析不来“棱镜偷家”的场面,于是只用一个棱镜和两个不朽就牵制住了AlphaStar的全部兵力。

在拖出自己的高科技部队后,MaNa一波推平了只会爆追猎的AlphaStar,让这次AI和人类的对决以10:1收场。值得一提的是,AlphaStar并没有学会打出“GG”,MaNa只能把AI的建筑一个一个拆光取得胜利,让场面显得有些尴尬。
一力降十会
虽然以大比分取胜,但AlphaStar有些胜之不武。
以第四局为例,AlphaStar选择了纯追猎者部队的打法,MaNa及时出不朽者(俗称“不朽爹”,对追猎是优势对抗)应对。
在针对MaNa主矿的进攻中,可以看到虽然AlphaStar的闪追猎(将受损的追猎闪烁到阵形后排、避免损失)操作极为精湛,但因为兵种劣势并未取得战果,甚至让MaNa防守出了兵力优势。

此时兵力大优的MaNa转守为攻,选择主动出击。但噩梦一般的画面出现了,在地图的中央,AlphaStar的追猎者持续不断地不同角度出现,牵制住了MaNa的大部队。
面对从三个方向的战争迷雾中杀出的追猎,MaNa完全迷失了进攻重心,不朽者损失惨重,只能回撤,最终因为兵力差距被AlphaStar一举拿下。
这次“被翻盘”一部分是因为MaNa判断失误,在大优的局面下贸然进攻,给了AlphaStar分割包围的可趁之机。但,这完全是建立在AI超出常人的操作强度上的。
在这段“三线闪追猎”的神仙表演中,AlphaStar的瞬时EPM(每分钟有效操作数)超过了1000,峰值甚至能达到1600。

MaNa在随后的采访中也面露苦笑,“这种情况在同水平的人类对局中不可能出现。”

虽然DeepMind对AlphaStar的EPM均值有所限制(基本和人类水平保持一致),但并没有限制AlphaStar的操作峰值。
这让AlphaStar在平时的闲散操作中“保存”下来的操作量,在关键战斗中一股脑地爆发了出来。
MaNa落败的主要原因,就是在大部分的关键战斗中被AS远超人类的操作强度碾压。即便AlphaStar在策略和运营上有一些亮点,大多也被“神仙操作”的光芒掩盖了。
另外,即便是限制了AI的EPM峰值,因为AI没有情绪波动、不会手滑点错,其操作效率也远高于人类,同等的EPM下仍然是人类劣势。
从比赛中我们也能看到,AI对每个追猎的操作都十分精准,攻击目标的优先级永远保持在“敌方农民>正在折跃的单位>其他单位”上。
这就有种“你以为你在和AI玩RTS,实际上AI在跟你打MOBA”的感觉。
制造纯粹的力量压制,显然不是DeepMind创造AlphaStar的意义。
AlphaStar的价值在哪里?
尽管AlphaStar的胜利很大一部分来自 “超人”的操作,但如果我们抛弃胜负本身,就能看到更有价值的事情——AlphaStar有不少操作和运营的思路和当前的人类选手完全不同,就像它的兄弟AlphaGo下出人类无法理解的棋路一样。
例如,在用凤凰对抗机械哨兵和不朽者的混合部队时,绝大多数人(包括职业选手)的直觉都是用凤凰“抬”(持续控制)威胁更大的不朽者,但AlphaStar的判断是抬哨兵效率更高,战斗的结果也证实了AI的判断。

在经济决策上,AlphaStar选择在一矿就出到24个农民,这也是人类职业选手从未有过的操作,显然来自AI的自我学习。有趣的是,赛后的数据统计显示AlphaStar的策略有着明显优势。
虽然AlphaStar的操作过于强力,但和几年前人工编写的脚本“悍马2000”相比,这些操作也都是AlphaStar在和自己的练习中自行学会的。

AlphaStar之所以偏爱出追猎者,正可能是因为它通过学习发现,在极高的操作准确率和高APM下,追猎的操作空间比起其他兵种更大、回报更高。

虽然目前的AlphaStar在决策上还有很多稚嫩的地方,MaNa也是依靠AlphaStar的经验漏洞,才取得了宝贵的一胜。
从今天的对局来看,真正的人类顶级选手面对这个版本的AlphaStar显然是有一战之力的。如果对AI的操作强度加以限制,人类的赢面会更大。
但DeepMind创造AlphaStar的目的并不是要赢人类,而是借助《星际争霸2》来研究“双方信息不透明”情况下的博弈对抗,进而把学习环境的架构和理念还延伸到其他领域。
而AlphaStar对《星际争霸2》的征途,已经跨过了最难的“从0到1”那关,接下来的事情,是从1到∞。
假以时日,AlphaStar或许就能像AlphaGo那样,创造出完全超越人类思路的运营策略,重新改写人类对《星际争霸2》的理解。
2月15日,还将有另外一个AI去挑战目前全球排名第2的世界冠军Serral。不过,这场比赛可能意义没那么大——参赛AI的行为逻辑基于人工编写的脚本,思考模式并没有AlphaStar这么“高级”。
“真正的AI”和“真正的人类顶级选手”之间的战斗,还没有来临。